


The majority of 3D software out today, from Disney’s modeling tools (Maya) to any popular game engine (Unreal/Unity/Crysis) or engineering CAD (SolidWorks, AutoCAD) use programming libraries that define low-level tasks to simplify and hasten the development workflow.
Almost all 3D software can be expected to do low-level tasks such as draw a 3D model in 2S space, texture an oblique surface, or draw shadows. As such, it does not surprise me that innovations such as OpenGL or DirectX were created to satisfy these needs. Rather than half-heartedly teach the computer these low-level tasks every time a new software needs to be created, the code is consolidated into API’s, essentially collections of tools designed specifically to be reused for different purposes.
As a bonus, much more time can be spent optimizing these tools, finding the quickest and best-organized methods to go about 3D computing. These API’s represent elapsed lifetimes of coordination between graphics card companies, developers, big computing corporations, artists, and mathematicians.
That said, understanding these basic tools is ideal for any graphical programmer. Dr. Ian Malcolm from Jurassic Park (one of the only movies I can sit down long enough to watch) seems to articulate this position very well:
You didn’t earn the knowledge for yourselves, so you don’t take any responsibility for it. You stood on the shoulders of geniuses to accomplish something as fast as you could, and before you even knew what you had, you patented it, and packaged it, and slapped it on a plastic lunchbox, and now you’re selling it, you wanna sell it.
While a DirectX game is typically not as dangerous as a park, which releases dinosaurs when it rains, I still feel that taking the time to write a custom renderer can help you understand how to work with 3D software in general and write more efficient and organized code.
However, it’s worth keeping in mind that any custom renderer I write will always be slower than a professional renderer because I cannot physically optimize in coordination with the graphics card company. Rather, most of the computation will be done with the CPU, which is not designed for graphical calculations. It’s a tradeoff, but that’s okay for learning.
That said, let’s get into it. In this article, I will cover efficient drawing to the screen.
Libraries to save time on menial code
To do anything meaningful in C++, a developer typically must include libraries, a set of tools to do basic things. It sounds familiar, right? However, unlike with graphical API’s, I have no desire to teach the computer trig or exponential functions, so I will include several standard libraries (libraries provided by Microsoft) and two nonstandard libraries (libraries not from Microsoft).
The standard libraries are needed for basic calculations, variable types, and file reading/writing, all basic stuff that doesn’t need much announcement. The two nonstandard libraries I have included, SDL and SDL_ttf are designed for 2D graphics, so I don’t think it’s cheating to include them. I’m using SDL to create a window and actually draw to the frame, and SDL_ttf to write text.
Per-Pixel Drawing
In theory, if you had the ability to have the computer write a specified color to a specified pixel, you could create any image the screen could physically support. For this reason, new C++ programmers are often drawn to the SetPixel() command(from windows.h), which requires just a few more parameters than that.

However, this convenience comes at the cost of efficiency. A typical modern computer screen has over a million pixels, and calling the SetPixel() function even once for every pixel is unacceptable. Here’s why.
Imagine that an artist is tasked with creating a painting that must be done exactly as the commissioner has in mind. However, the commissioner can only communicate with the artist by passing him slips of paper. A simple solution could be to pass over a million notes to the artist, each including a position to paint and a color for an individual stroke.
However simple the task of drawing a simple brushstroke, it does take some time to pick up the brush and color pallet for each instruction. With that goal, an acceptable method of quick painting, in this hypothetical circumstance, could be to agree on a code beforehand to convert numbers into image data, then the commissioner to give the artist one big slip of paper containing all of the information for the painting, and then another telling him to actually paint the information.
The artist (CPU/GPU) no longer switches between receiving/interpreting messages from the commissioner (software/programmer) and painting for each instruction, allowing the job to be done much quicker.
The Buskmiller Solution
The solution I went with, by no means an innovation, is to store the information for the screen in an array, or collection, of Uint32’s. Recall that computers can store the smallest unit of information in a bit, containing a binary value (0 or 1, true or false, chemistry class or living a meaningful life, etc.).
To store information that needs more than a binary state, computers string together bits. For instance, if I have a variable that can be 16 values, I could store it in four bytes, as each combination of binary values would yield a different value for the variable (2^4 = 16).
For this reason, we come to find that the powers of two are very efficient and convenient to work with. Fortunately, graphical programmers have settled on using color values from 0 – 255 for each color channel, red, blue, and green.
Thus, a single channel can be stored in eight bits, as 2^8 = 256, the total number of values from 0 – 255. In C++ for windows, the Uint32 data type can store 32 bits, equal to three channels or one color. An entire screen can be stored in an array of Uint32’s the size of the width times the height.
Note that this is a one-dimensional array, which means we have to resort to a slightly hacky method to manipulate a pixel. Here’s my function to change a single value in a Uint array:
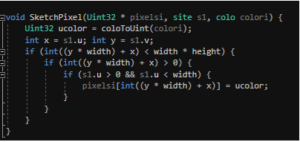

The ‘u’ member represents the horizontal location, while the ‘v’ member represents the vertical location. Sometimes ‘u’ and ‘v’ are preferred, as they cannot be confused for the x and y, typically used for 3D coordinates. “Colo” is also a struct, which stores color in not three, but four channels. The fourth channel, typically called “alpha”, stores information based on the opacity of the color.

Each image of LeVar Burton contains the same RGB information, yet interacts with the red background differently based on their alpha. It’s very difficult to get a good look at LeVar at 50% alpha, which is why it’s important to set alpha values correctly. My coloToUint function converts RGBA to its RGB lookalike, assuming the background is always a particular grey.
This is a cheap approximation, not considering the actual color already at the pixel, but it works for what I try to do. Because alpha only deals with two images interacting, we need to take it out to write to the screen. The x and y variables convert the decimal (float) values of the site to integer values, as pixels are typically described that way.
The series of if statements ensure that the specified point is in the array or describes an actual pixel on the screen. If we don’t make sure that these conditions are met, we might accidentally draw to unallocated memory and crash the program.
So, as of now, that which must be done to draw a pixel to the screen is to create a site and a colo, then call the function.
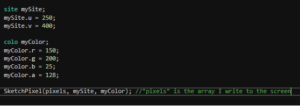
Fortunately, converting the array to an image and displaying it is simple with SDL. My implementation of this process is unnoteworthy(SDL_UpdateTexture(), SDL_RenderCopy() after draw calls), so I’ll leave it out.
Next time I’ll discuss how to draw lines and my implementation of the camera transformation algorithm. If you like have any questions or hate mail for me, feel free to email me. I’m 19046@jcpstudents.org. Make sure to stay tuned to The Roundup for the next installments in my computer science column.
")


